Diarization Error Rate#
Diarization Error Rate (DER) is an important metric used to evaluate speaker diarization systems. It quantifies the overall performance of a speaker diarization system by measuring the ratio of the duration of errors to the total ground truth speech duration. DER is calculated as a score bounded below by 0 — 0 being a perfect match, with the score increasing as the duration of errors increases.
Implementation Details#
Background#
To simplest way to quantify the error in a candidate diarization is to measure the duration of false alarms, missed detections, and speaker confusions. These three elementary errors form the building blocks of diarization error rate.
False Alarm
False alarm is duration of non-speech classified as speech — analagous to false positive diarizations. Using the following hypothetical ground truth and inference diarization segments, let's calculate our false alarm duration.
from pyannote.core import Segment, Annotation
ground_truth = Annotation()
ground_truth[Segment(0, 10)] = 'A'
ground_truth[Segment(13, 21)] = 'B'
ground_truth[Segment(24, 32)] = 'A'
ground_truth[Segment(32, 40)] = 'C'
inference = Annotation()
inference[Segment(2, 14)] = 'A'
inference[Segment(14, 15)] = 'C'
inference[Segment(15, 20)] = 'B'
inference[Segment(23, 36)] = 'C'
inference[Segment(36, 40)] = 'D'
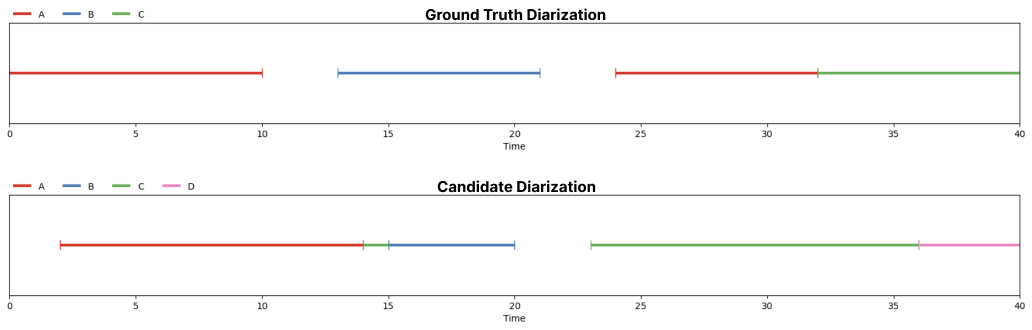
Upon inspection, at time segments [10, 13] and [23, 24], our candidate diarization contains speech that
doesn't exist in the ground truth diarization. Thus, our false alarm is equal to \(3 + 1 = 4\) seconds.
Missed Detection
Missed detection is the duration of speech classified as non-speech — analagous to a false negative in our diarizations. Using the previous example, let's calculate our missed detection duration.
The model failed to detect speech at time segments [0, 2] and [20, 21]. Thus, our missed detection detection
sums up to 3 seconds.
Speaker Confusion
Speaker confusion is the duration of speech that has been misidentified. Once again, let's use the previous example to calculate our speaker confusion duration.
In the segment [13, 14], our candidate misidentifies speaker B as speaker A. In segment [14, 15], our
candidate misidentifies B as C. In segment [24, 32], the candidate misidentifies A as C. Finally,
in segment [36, 40], C is misidentified as D. In total, our speaker confusion amounts to 14 seconds.
Definition#
Formally, DER is defined as the duration of false alarm, missed detection, and speaker confusion errors divided by the ground truth duration.
Example#
Using the following time segments, let's calculate the DER of the candidate text.
from pyannote.core import Segment, Annotation
ground_truth = Annotation()
ground_truth[Segment(0, 5)] = 'C'
ground_truth[Segment(5, 9)] = 'D'
ground_truth[Segment(10, 14)] = 'A'
ground_truth[Segment(14, 15)] = 'D'
ground_truth[Segment(17, 20)] = 'C'
ground_truth[Segment(22, 25)] = 'B'
inference[Segment(0, 8)] = 'C'
inference[Segment(11, 15)] = 'A'
inference[Segment(17, 21)] = 'C'
inference[Segment(23, 25)] = 'B'
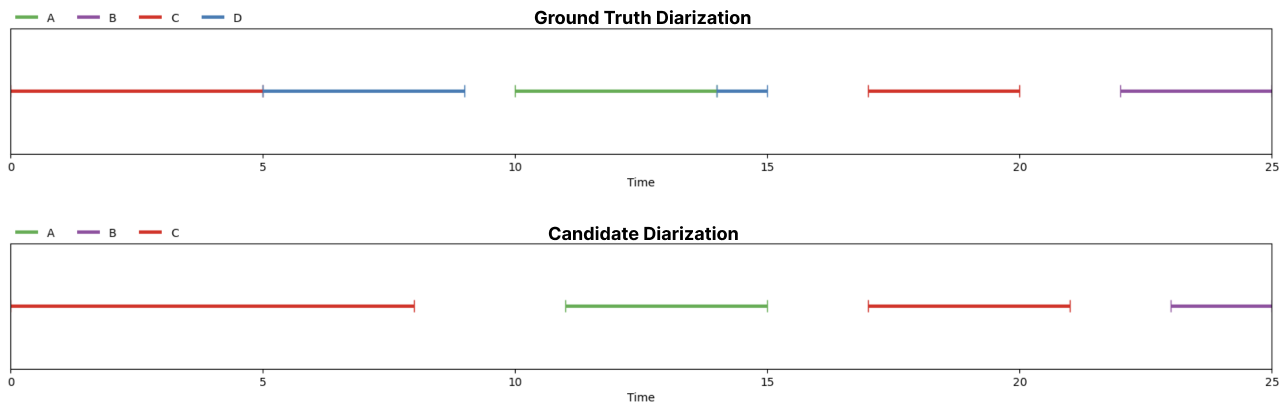
Step 1. Calculate Error Durations
False Alarm
Our candidate diarization contains speech that doesn't exist in the ground truth diarization at time
segment [20, 21]. Our false alarm duration is 1 second.
Missed Detection
Our model fails to detect speech at time segments [8, 9], [10, 11] and [22, 23]. Our missed detection
duration is 3 seconds.
Speaker Confusion
Our candidate misidentifies speaker D as C at time segment [5, 8] and misidentifies speaker D as A
in segment [14, 15]. Our speaker confusion duration is 4 seconds.
Step 2. Calculate Diarization Error Rate
Using the formula, we get:
$$ \begin{align} \text{DER} &= \frac{\text{false alarm} + \text{missed detection} + \text{speaker confusion}}{\text{ground truth duration}} \ &= \frac{1 + 3 + 4}{20} \ &= 0.4 \end{align} $$
Our diarization error rate is 0.4.
Limitiations and Biases#
Though DER provides a strong insight into the accuracy of speaker labels and predicted segments, it fails to pinpoint the specific components of a speaker diarization system that may cause it to perform poorly. As such, it is a good metric to evaluate the overall performance of a diarization system, but should be used alongside targeted metrics such as detection error rate and segmentation coverage to evaluate the individual models that detect voice activity, or speaker changes. Furthermore, diarization error rate does not place any weight on the accuracy of generated transcript texts, as it is used solely to measure the error in a diarization system.