Nesting Test Case Metrics#
When computing test case metrics in an evaluator, in some cases it is desirable to compute multiple sets of aggregate metrics within a given test case.
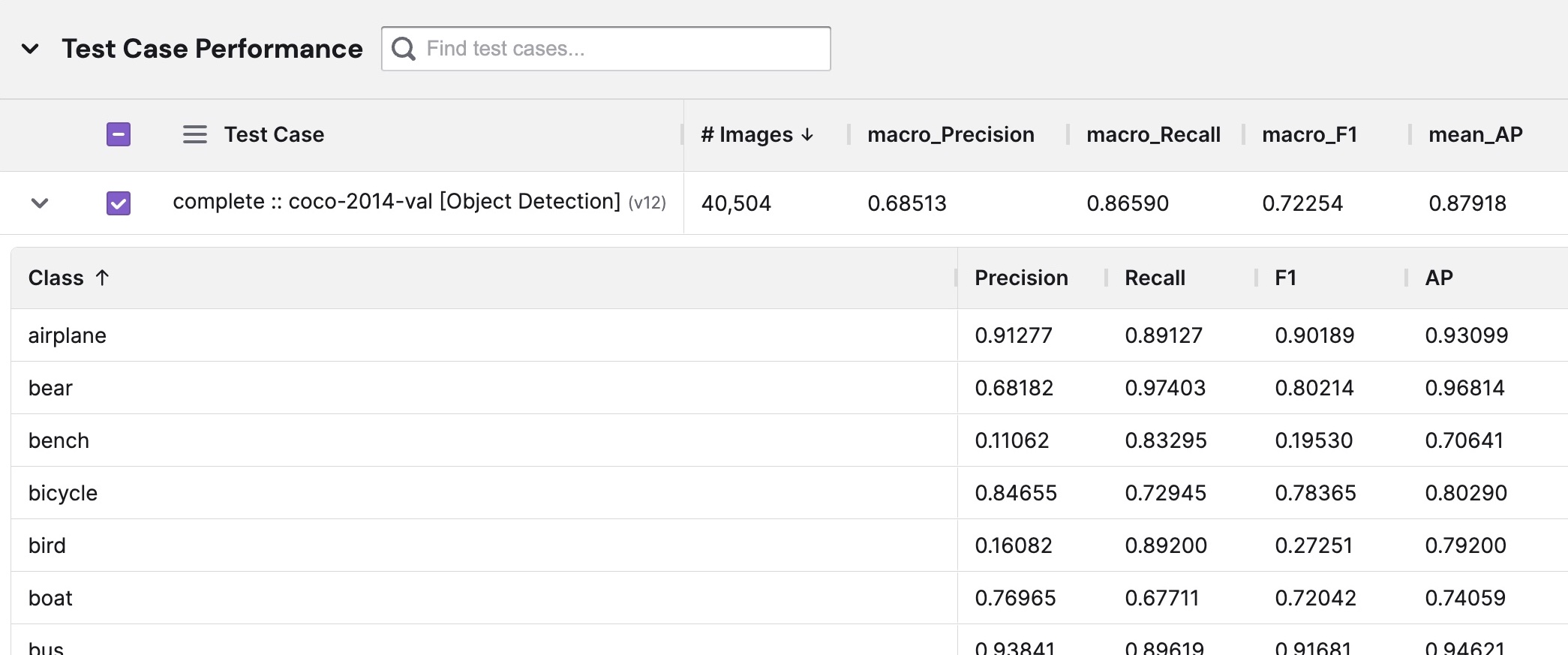

Class-level metrics for the airplane, bear, bench, etc. classes reported for the test case complete :: coco-2014-val [Object Detection]
Here are a few examples of scenarios where this pattern might be warranted:
| Use Case | Description |
|---|---|
| Multiclass workflows | For ML tasks with multiple classes, a given test case may contain samples from more than one class. While it's useful to report metrics aggregated across all classes using an averaging method, it's also useful to see aggregate metrics computed for each of the classes. |
| Ensembles of models | When testing an ensemble containing multiple models, it can be useful to see metrics from the output of the complete ensemble as well as metrics computed for each of the constituent models. |
| Model pipelines | When testing a pipeline of models, in which one model's output is used as an input for the next model, it can be difficult to understand where along the pipeline performance broke down. Reporting overall metrics as well as per-model metrics for each model in the pipeline (the metrics used can differ from one model to the next!) can help pinpoint the cause of failures within a pipeline. |
In these cases, Kolena provides the API to nest additional aggregate metrics records within a
MetricsTestCase object returned from an evaluator. In this tutorial, we'll learn
how to use this API to report class-level or other nested test case metrics for our models.
Example: Multiclass Object Detection#
Let's consider the case of a multiclass object detection task with objects of type Airplane, Boat, and Car.
When a test case contains images with each of these three classes, test-case-level metrics are the average (e.g.
micro, macro, or
weighted) of class-level metrics across each of these three classes.
For this workflow, we may consider using macro-averaged precision, recall, and F1 score, and mean average precision score (mAP) across all images as our metrics:
| Test Case | # Images | macro_Precision |
macro_Recall |
macro_F1 |
mAP |
|---|---|---|---|---|---|
| Scenario A | 2,500 | 0.91 | 0.99 | 0.95 | 0.97 |
| Scenario B | 1,500 | 0.83 | 0.96 | 0.89 | 0.91 |
At the API level, these metrics would be defined:
from dataclasses import dataclass
from kolena.workflow import MetricsTestCase
@dataclass(frozen=True)
class AggregateMetrics(MetricsTestCase):
# Test Case, # Images are automatically populated
macro_Precision: float
macro_Recall: float
macro_F1: float
mAP: float
These metrics tell us how well the model performs in "Scenario A" and "Scenario B" across all classes, but they don't tell us anything about per-class model performance. Within each test case, we'd also like to see precision, recall, F1, and AP scores:
Class |
N |
Precision |
Recall |
F1 |
AP |
|---|---|---|---|---|---|
Airplane |
1,000 | 0.5 | 0.5 | 0.5 | 0.5 |
Boat |
500 | 0.5 | 0.5 | 0.5 | 0.5 |
Car |
2,000 | 0.5 | 0.5 | 0.5 | 0.5 |
We can report these class-level metrics alongside the macro-averaged overall metrics by nesting
MetricsTestCase definitions:
from dataclasses import dataclass
from typing import List
from kolena.workflow import MetricsTestCase
@dataclass(frozen=True)
class PerClassMetrics(MetricsTestCase):
Class: str # name of the class corresponding to this record
N: int # number of samples containing this class
Precision: float
Recall: float
F1: float
AP: float
@dataclass(frozen=True)
class AggregateMetrics(MetricsTestCase):
# Test Case, # Images are automatically populated
macro_Precision: float
macro_Recall: float
macro_F1: float
mAP: float
PerClass: List[PerClassMetrics]
Now we have the definitions to tell us everything we need to know about model performance within a test case:
AggregateMetrics describes overall performance across all classes within the test case, and PerClassMetrics
describes performance for each of the given classes within the test case.
Naming Nested Metric Records#
When defining nested metrics, e.g. PerClassMetrics in the example above, it's important to identify each row by
including at least one str-type column. This column, e.g. Class above, is pinned to the left when displaying nested
metrics on the
Results page.
Statistical Significance#
When comparing models, Kolena highlights performance improvements and regressions that are likely to be statistically significant. The number of samples being evaluated factors into these calculations.
For nested metrics, certain fields like N in the above PerClassMetrics example are used as the population size for
statistical significance calculations. To ensure that highlighted improvements and regressions in these nested metrics
are statistically significant, populate this field for each class reported. In the above example, N can be populated
with the number of images containing a certain class (good) or with the number of instances of that class across all
images in the test case (better).
For a full list of reserved field names for statistical significance calculations, see the API reference documentation
for MetricsTestCase.
Conclusion#
In this tutorial, we learned how to use the MetricsTestCase API to define
class-level metrics within a test case. Nesting test case metrics is desirable for workflows with multiple classes, as
well as when testing ensembles of models or testing model pipelines.